Siamo arrivati alla 3 lezione del corso seo gratis sul posizionamento di siti web sui motori di ricerca.
Nelle precedenti lezioni hai avuto modo di scoprire cos’è la seo e il seo, cosa sono le keywords e perché sono molto importanti. Abbiamo dato informazioni sui contenuti e le strutture di un sito web.
Oggi in questa lezione sul posizionamento di siti web, ci addentreremo nei meandri del codice HTML, parleremo del processo di indicizzazione di siti web, dei fattori che possono limitare i processi di indicizzazione sui motori di ricerca e dei fattori di ottimizzazione di siti web.
Come ci vedono i motori di ricerca
I motori di ricerca non vedono i nostri siti esattamente come li vediamo noi con i nostri occhi.
Un sito web non è altro che un insieme di documenti scritti in linguaggio HTML. Il codice HTML permette di creare documenti e pagine web richiamando risorse, immagini che risiedono sul nostro server oppure in altri punti della rete.
Per vedere un documento HTML apri una qualsiasi pagina web e premi il pulsante destro del mouse, possibilmente in un punto vuoto della pagina.
Tra le varie voci puoi leggere qualcosa del tipo: “Visualizza sorgente pagina”.
Il sorgente pagina è proprio il codice HTML e come abbiamo già detto, è il codice che i motori di ricerca leggono per capire come una pagina viene renderizzata (visualizzata).
La renderizzazione invece, viene fatta per noi essere umani dal browser, il programma come abbiamo già avuto modo di vedere che serve per navigare in internet e per vedere le pagine web.
Esempi di browser sono: Internet Explorer, Firefox, Chrome.. ecc.
Quindi il codice HTML è acronimo di Hypertext Markup Language e ci indica come una pagina è strutturata, dove sono locate le risorse (immagini, video, etc, fogli di stile), che caratteri e dimensioni utilizziamo, dove puntano i link , che tecnologie vengono usate (Ajax, Javascript, Flash)
Quello che segue è un piccolo documento HTML. Se tu incollassi su un file di testo il codice che vedi e salvassi il file con estensione “.htm” diventerebbe una pagina html completamente bianca.
Questo perché un documento HTML è formato da 2 macro parti:
- Head che contiene informazioni riguardanti il documento
- Il BODY che contiene i contenuti del documento
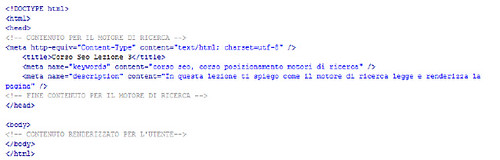
Come puoi notare nel nostro caso nel tag body è presente un solo commento, ovvero del codice non visibile in fase di renderizzazione.
Indicizzazione
Adesso che hai un minimo di basi di HTML, possiamo addentrarci nelle questioni tecniche riguardanti il nostro corso seo per il posizionamento di siti web.
Indicizzazione è il processo che permette al SEO (l’operatore), di facilitare al motore di ricerca l’archiviazione dei contenuti di un sito web.
L’indicizzazione può avvenire per diversi motivi tra cui:
- Il crawling da parte di spider del motore di ricerca
- Il modulo di suggerimento URL
- La fornitura di una mappa del nostro sito al motore di ricerca
- I feed rss
Il Crawling e i Link
I motori di ricerca seguono i link, per cui se vuoi che una pagina sia indicizzata, un buon modo è quello di mettere un link verso quella pagina da una pagina web che è attualmente indicizzata.
Puoi sapere se una pagina web è indicizzata cercando su Google, o sul motore di ricerca dove vuoi apparire, la stringa contenente l’URL completo della tua pagina web.
Suggerisci sito
Molti anni fa, i motori di ricerca avevano un modulo chiamato suggerisci link.
Era possibile attraverso quel modulo, suggerire le pagine web che lo spider avrebbe dovuto visitare.
Con l’introduzione delle Xml Site Map, questo strumento è diventato del tutto inutile e molti motori di ricerca non lo mettono più a disposizione.
Le XML Site Map
Le site map sono dei file XML e sono state introdotte dai motori di ricerca per facilitare il processo di indicizzazione dei contenuti. Si tratta di un metodo molto efficace per suggerire i documenti che voliamo indicizzare al motore di ricerca
Feed RSS
RSS è acronimo di Really Simple Syndication ed è un formato nato per la distribuzione dei contenuti sotto forma di XML. In altre parole i contenuti del nostro sito vengono separati dalla grafica e trasmessi solamente come contenuto puro.
I lettori di RSS possono quindi ricevere aggiornamenti in tempo reale dei nostri contenuti. Google e gli altri motori di ricerca sono molto sensibili all’esigenza di indicizzare informazioni fresche e recenti. Per questo motivo è possibile che i nostri contenuti siano indicizzati dopo pochi minuti dalla generazione
Impedire l’indicizzazione con il file robots.txt
Così come possiamo cercare di fare in modo che i motori di ricerca indicizzino i nostri siti web, allo stesso modo possiamo cercare di scoraggiarli a archiviare le informazioni dei nostri contenuti.
Esistono diversi metodi per scoraggiare i motori di ricerca ad indicizzare le nostre pagine, e oggi ne segnalo 3.
Il file robots.txt è un protocollo nato nel 1993 dai membri della robots mailing list ([email protected]) ed è un protocollo che segnala le regole di comportamento che gli spider che visitano il nostro sito dovrebbero seguire. (Ho parlato degli spider nel post precedente l’importanza dei contenuti in un progetto seo, dicendo che sono dei software automatici che scandagliano la rete in cerca di informazioni..)
Il file robots.txt va posizionato nella directory principale del vostro sito web ed è molto utile per bloccare gli strumenti esterni di analisi dei link che vedremo nelle prossime lezioni.
La sintassi del file robots.txt è molto semplice
La stringa “User-agent” identifica il nome dello spider che visita il nostro sito
“Disallow” indica che lo spider non può accedere a determinate cartelle o file..
Es.:
User-agent: Majestic-12
Disallow: /
Stiamo dicendo che il robot di Majestic SEO che è un analizzatore di link non deve poter accedere al nostro sito. Infatti i link analizzati da Majestic Seo, potrebbero essere utili ai nostri concorrenti per cercare di superarci nel posizionamento web.
Ti consiglio di includere nel tuo robots.txt i seguenti codici:

Impedire l’indicizzazione con il meta robots
Se non hai la possibilità di accedere alla directory principale del tuo sito puoi utilizzare un elemento del codice HTML posizionabile all’interno del tag HEAD.
Il meta name ROBOTS indica se la pagina può essere indicizzata oppure no dal motore di ricerca e se il motore di ricerca può seguire i link contenuti in quella pagina per indicizzare altre eventuali pagine.
<meta name=“robots” content=”index (oppure noindex), follow (oppure nofollow)” />
Impedire l’indicizzazione con il file .htaccess
Il file .htaccess è un file di configurazione di web server in ambienti Unix-like.
Se il tuo sito è hostato su una macchina linux, molto probabilmente il tuo web server sarà Apache e hai quindi la possibilità di utilizzare il file .htaccess per garantire autorizzazioni e accessi al tuo sito, gestire le pagine di errore personalizzate, riscrivere l’url (ti spiego meglio dopo..) e il controllo della cache (anche questo lo spiego nel dettaglio dopo..)
Al momento limitiamoci a dire che attraverso opportuni codici è possibile rendere dei contenuti inaccessibili.
Vedi l’esempio nell’immagine:
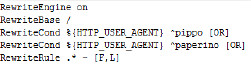
Possiamo tradurre come:
Se lo user agent è pippo oppure paperino rendi il sito inaccessibili. Ovvero ciò avviene grazie alla F che indica forbidden mentre “L” indica Last Rule
Qui puoi trovare un ottimo tutorial in inglese sulla sintassi dell’.htaccess
Contenuti duplicati e URL dinamici
Dopo aver visto come noi webmaster possiamo cercare di impedire a terzi di visualizzare il nostro sito web, o determinati contenuti, vediamo anche come e perché certi tipi di contenuti siano automaticamente resi inaccessibili dagli stessi motori di ricerca.
Quando abbiamo parlato dell’importanza dei contenuti abbiamo dato molto valore alla qualità dei contenuti, dicendo che devono essere originali e non copiati.
I contenuti copiati sono detti contenuti duplicati e i motori di ricerca, primo fra tutti Google, non li vede di buon occhio, tanto che penalizza i siti che pubblicano contenuti duplicati de indicizzando la pagina che contiene contenuti copiati oppure mettendola in una specie di “limbo” delle pagine con contenuti duplicati visualizzabili solamente quando l’utente che effettua la ricerca clicca su uno speciale link con l’anchor text “mostra i risultati omessi”.
Quindi i contenuti duplicati sono dannosi perché possono portare a penalizzazioni e alla de-indicizzazione delle pagine che li contengono.
Ma una forma di contenuti duplicati può anche essere generata attraverso gli url dinamici.
Ipotizza che la stringa http://miosito.com/?contenuto=1a potrebbe mostraci la home page di un sito. La logica interna di programmazione prende il valore “1a” del parametro “contenuto” e capisce che deve mostrare la home. È ovvio che solo il programmatore è consapevole di come si comporta il suo sito e che se l’utente chiedesse la pagina http://miosito.com/?contenuto=1a2 magari per via di qualche errore di programmazione possa essere rimostrata la pagina home.
Per i motori di ricerca però i due URL indicano 2 pagine diverse ma presentono lo stesso contenuto. Siamo di fronte nuovamente a dei contenuti duplicati.
Per ovviare a questo problema è necessario riscrivere l’URL e possiamo farlo dal file .htaccess.
Spostamento dei contenuti
L’.htaccess ci permette inoltre di gestire le pagine morte del nostro sito.
I contenuti hanno una posizione nel server dove sono locati e i motori di ricerca la conoscono e la presentano agli utenti attraverso la serp.
Se spostiamo un file da una posizione ad un’altra, il motore di ricerca continuerà ad indicare agli utenti la vecchia posizione che troveranno una pagina bianca oppure un errore 404 (Pagina non trovata).
Attraverso il Redirect 301 di tipo permanente e il Redirect 302 di tipo temporaneo possiamo dire ai motori di ricerca che la risorsa che hanno archiviato può essere visitata in un’altra location, e eventualmente se sia il caso di aggiornare il loro archivio dicendogli se il redirect ha carattere temporaneo o definitivo.
Fattori di ottimizzazione
Per ottimizzare una pagina web o un sito dobbiamo tenere in considerazione la velocità di download dei contenuti. Inoltre anche la quantità e il tipo di processori del server su cui il nostro sito è mantenuto, la memoria, la banda, la posizione geografica, la connessione internet, la dimensione delle pagine, i tipi di risorse contenuti nelle pagine, influiscono sull’ottimizzazione di una pagina web.
Il Caching
Siti costruiti con i CMS (Content Management System), strumenti come WordPress e Joomla, eseguono centinaia di query verso i database interni.
Abilitare il caching permette di limitare il numero di query verso i DB e offrire una pagina alternativa di copia ai nostri utenti. In questo modo solo il primo utente che richiede la pagina deve attendere i tempi di ricerca sul database mentre per tutti gli altri la richiesta sarà più veloce.